
Deepseek V3.1 看似只是一次版本迭代,实则是迈向“通用智能”的关键一步。本文全面解析新版本的能力提升、使用场景与背后意义,帮助你理解这款国产大模型如何在技术演进中稳扎稳打,走出自己的节奏。
Deepseek V3.1的发布
8月19日,Deepseek团队官方宣布名为Deepseek V3.1的版本更新,并于2天后正式官方发文。作为国产AI的“杠把子”价格最低 Flux api,向来低调的Deepseek团队任何的动作都注定会引来各方关注。在下不才,经过这些天的集中式搜集,希望能够在本文为各位朋友全面介绍本次Deepseek V3.1,包括都有哪些更新,分别意味着什么,坊间对于本次更新又有哪些夸赞与吐槽。甚至你会看到,本次Deepseek更新是如何仅凭一句话,就推动了8月22日国产芯片股的集体暴涨。
Deepseek V3.1 更新了什么
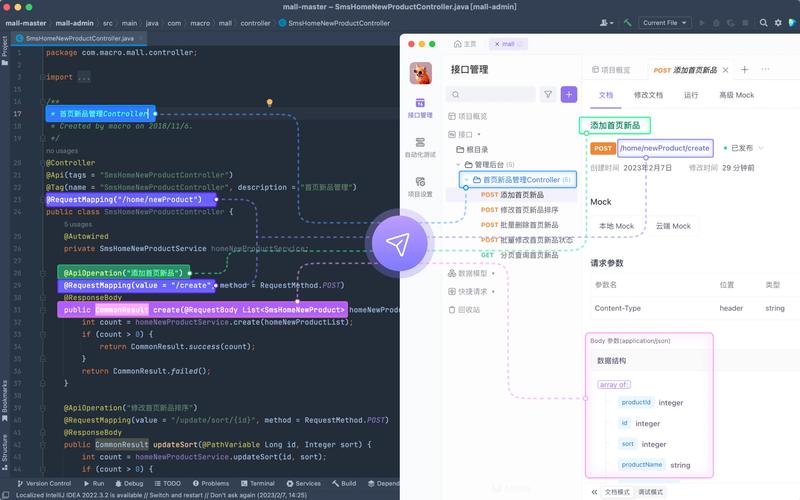
在最开始的8月19日,Deepseek在其官方群里宣布了线上模型版本已升级至V3.1。从下面的截图我们可以看到,关于Deepseek V3.1 的更新内容,最开始Deepseek的宣传点是“上下文长度拓展至128k”。但一直关注Deepseek的各种人士都知道,此前的Deepseek的开源版本早已支持128K上下文,只是官方仅开放至64K,现在算是对齐了。
应该说kong api,上下文长度提升对于日常使用的体验肯定是有所提升的。不过,以Deepseek“不鸣则已,一鸣惊人”的性格,断然是不会因为这么一点更新就刷一个新的版本号(要知道,之前像V3-0324,R1-0528这么大的更新,也就刷了个日期号)。于是,各方人马纷纷开始了各种体验。
果然,两天后的Deepseek官方发文价格最低 Midjourney 接口,口径就发生了变化,称之为“迈向 Agent 时代的第一步”(确实,只有这么个级别的更新,才配得上一次版本号更新)。我们具体来看看,这回Deepseek V3.1版本除了前面的“上下文长度拓展至128k”,都有哪些更新。
官方文章在开篇就给出了三点。第一点,混合推理架构。我们知道,此前Deepseek的模型,按照推理和非推理,是分为R1和V3两个模型的。这次版本,Deepseek团队就将这两个模型进行了合并,也就是一个模型同时支持思考模式与非思考模式。不过它和GPT-5的自动路由机制不同。GPT-5是模型自己根据用户的提问来判断是否要调用推理模型,而DeepseekV3.1依然是用户控制。
尽管我们都不是AI方面的技术专家。但也不难猜测,要将两个独立的AI模型合并应该不是一件简易的事。那为什么Deepseek团队要费劲合并两个模型呢?那肯定是因为“收益大于付出”嘛,这就得提到后续的第二点、第三点了。

首先是更高的思考效率。按照官方的说法,“经过思维链压缩训练后,V3.1-Think 在输出 token 数减少 20%-50% 的情况下,各项任务的平均表现与 R1-0528 持平”,“同时,V3.1 在非思考模式下的输出长度也得到了有效控制,相比于 DeepSeek-V3-0324 ,能够在输出长度明显减少的情况下保持相同的模型性能”。
思考效率的提升直接带来的收益就是API价格的下降,这对于各大开发者就是实打实的“帮家人们把价格打下来”了。我们来对比一下,Deepseek的API价格变化。
国外也有用户汇总整理了各个主流模型的性价比,从下表中可以看到,Deepseek V3.1的性价比同样名列前茅。
然后是更重要的DeepSeek api key,更强的Agent能力。AI Agent这个名词已多次出现在我们过往的讨论当中,它的本质之一就是AI大模型能够自行根据需要,合理地调用各类工具来解决复杂问题。在官方析出的材料中,包含了涉及编程、工具调用、网页浏览、终端操作等多个衡量智能体能力的基准测评结果。从结果来看,本次DeepseekV3.1在这些测评中的表现对比之前的版本都有显著提升,这些都为构建更强大的AI智能体应用提供了更多的可能性。
编程智能体:
搜索智能体:
介绍完官方宣传中最主要的三项更新,还有一处信息我需要特别指出的,那就是藏在文章中的这一句话“需要注意的是,DeepSeek-V3.1 使用了 UE8M0 FP8 Scale 的参数精度”。这里的“UE8M0 FP8 Scale”是AI模型部署到算力硬件时的一种压缩技术,能够有效地降低模型大小和计算成本,同时保持模型的性能和精度。Deepseek官方专门在评论区留言补充道“UE8M0 FP8是针对即将发布的下一代国产芯片设计”,也就是说,这是下一代国产芯片专用的技术。就是这一句话直接推动22号大A国产芯片股的集体上涨,“寒王”寒武纪更是在此前的高股价下直接20%涨停。之前坊间一直就有流转Deepseek的下一代R2模型会全面适配采用国产算力芯片,这下算是实锤了二者的深度绑定。
对于Deepseek V3.1的夸赞与吐槽
在距离此次V3.1发布的一周多后DeepSeek api key,我利用Deepseek总结了目前网络上用户对于这次新版本的使用感受,并按“夸赞”和“吐槽”进行分类。
我们先来看看“夸赞”的内容,其实基本上与这次版本的更新内容是重叠的,因此我们也不作展开论述。
说实在的,外网对DeepSeek V3.1的整体评价仍然是积极占主导,吐槽方面不算多。如果硬要再补一条,那就是“期待落空”。即传说中的R2推理模型还是没见着,用户提到像多模态能力仍然缺失,在功能全面性有所不足。这方面基本上跟我之前一次关于R2的可能更新方向是重叠的。
总结:Deepseek的“一小步”
DeepSeek-V3.1的混合推理架构被视为大模型发展的一个重要方向。它标志着行业竞赛的重点正从一味追求参数规模,转向如何更精巧地整合多种能力于一体,并在性能、速度、成本之间找到最佳平衡点。
此外,模型的Agent能力也将会是后续重点发展的方向。Agent能力指向的是AI模型解决复杂问题的能力,这一点从这次Deepseek官方的宣传点“迈向Agent时代的第一步”便可得知,毕竟,得先有“Agent时代”存在,才有“迈向第一步”这么一说嘛。
还有就是对于国产芯片的支持。在AI三要素——模型、数据、算力——当中,算力是目前我们依然被卡脖子的、亟待突破的领域。而Deepseek推动“软硬结合”的做法,有助于打破卡脖子,推动我国AI产业建立从底层芯片、算法框架到上层应用的闭环体系。
我将V3.1的更新称为Deepseek的“一小步”,无论是混合推理模型、Agent能力、国产芯片软硬结合,都是面向未来却又充满未知的领域。这些探索,可能成功,亦可能失败,但我们不能也不甘于永远都在AI行业充当一个“追赶者”的角色,总需要有人去到这些领域尝试开拓。
愿Deepseek的“一小步”,能成为国产AI的“一大步”。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...