在当今技术和数据驱动的时代,理解各种评估工具和指标变得越来越重要。其中,”bias指标”是一个关键概念,常在统计分析、机器学习、人工智能等领域中讨论。本文将深入探讨bias指标的含义、应用场景以及如何通过几个实际案例评估其影响。
什么是Bias指标?
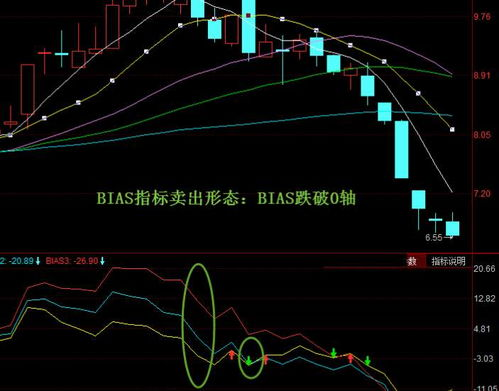
“Bias”在英文中通常指的是偏差或偏见。在数据科学和机器学习的领域,Bias指标用来衡量一个模型在预测时与真实情况之间的误差。简而言之,它是一个衡量系统偏差的数值表达。当我们构建模型或算法时,理想目标是确保它能够公正、准确地反映现实情况。由于数据收集的偏差、处理方法或模型本身的限制,导致结果偏离真实值,这种偏离程度即为Bias指标所反映。在统计学中,Bias是指估计值的期望与真实参数值之间的差距。较低的Bias指示了更准确的模型或算法。
为何需要关注Bias指标?
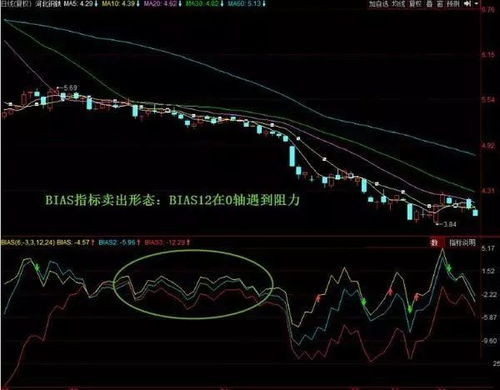
掌握Bias指标对于开发和评估预测模型至关重要。一个高偏差的模型可能意味着过于简化现实,或是未能充分学习训练数据的复杂性,这在机器学习中被称为欠拟合。相反,追求极低的Bias也可能引导模型对训练数据过度敏感,导致过拟合,即模型在新数据上的泛化能力差。因此,数据科学家和机器学习工程师需要找到Bias和Variance(方差,另一个衡量模型泛化误差的重要指标)之间的最佳平衡点,以构建既准确又具备良好泛化能力的模型。
Bias指标在不同领域的应用
在多个行业和研究领域,Bias指标都有广泛的应用。,人工智能领域,特别是在自然语言处理(NLP)和图像识别中,Bias指标帮助开发者识别和纠正算法偏见。在社会科学研究中,理解和分析Bias指标能够揭示调查结果可能的系统性偏差。在医疗健康领域,Bias指标用于评估临床试验结果的准确性和可信度。通过准确评估Bias指标,研究人员和实践者能够采取措施减少偏差,从而提高结果的可靠性和公平性。
实战案例分析与评估
考虑到Bias指标的重要性,让我们来看几个具体的案例分析。在机器学习项目中,数据科学家常通过交叉验证、Bootstrap等技术减少Bias。,一个面向银行贷款审批模型的案例中,通过引入多样化的训练数据和实施公平性校准算法,成功降低了模型对于不同群体的偏差。在健康医疗研究里,通过对照组设计和随机分配实验对象,可以有效控制Bias,提高研究的可信度。这些案例展示了通过细致的策略和技术实施,如何实现对Bias的有效管理和减少,进而提升模型和研究的整体质量。
Bias指标是理解、评估和优化任何预测模型不可或缺的一部分。它帮助我们诊断模型的准确度和公平性,为降低偏差提供了方法和方向。通过中肯的评估和合理的权衡,我们能够构建更加准确和公正的数据驱动决策工具。无论是在社会科学、医疗健康还是人工智能领域,理解并有效管理Bias指标,都是实现科技进步和社会发展的关键。
 微信扫一扫
微信扫一扫 版权:文章归 神灯指标 作者所有!
转载请注明出处:https://www.177911.com/1468.html











还没有评论呢,快来抢沙发~