

大家好!刚刚结束了一个对我们 SaaS 产品来说强度非常大的 OpenAI API 调用月价格最低 OpenAI api,我想顺便分享一些踩坑总结。通过下面这几条优化策略,我们成功将成本降低了 43%!希望这能帮到同样也在用 OpenAI API 的开发者朋友们。

选对模型是关键中的关键
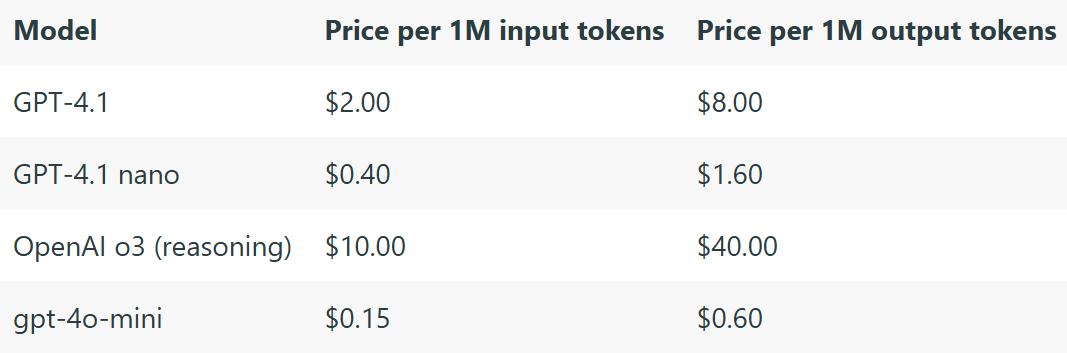
我知道这听起来像废话,但这真的很重要。不同模型之间的价格差距巨大,我们通过大量测试,最终挑选了“最便宜但效果还不错”的组合:简单任务主要用 GPT-4o-mini,复杂一点的才上 GPT-4.1。
我们的业务并不需要强逻辑推理能力的模型(比如 GPT-4 Turbo),所以可以放心避开高价位的模型。虽然测试确实花了不少时间,但从长期来看绝对值得。
用好提示词缓存(Prompt Caching)
这点完全是意外收获。OpenAI 平台会自动缓存完全一致的提示词(prompt),在重复调用相同的 prompt 时价格最低 OpenAI api,不仅速度提升,成本也能大幅下降!
我们实测发现:对于长提示词,延迟最多减少 80%,成本也降低近 50%。还有一点很重要:确保 prompt 中的“变化部分”放在末尾,否则缓存机制可能无法命中。除了这一点OpenAI Plus api,其他都不用额外配置,真的省心又高效。
务必设置账单预警!
一定要开通账单提醒!我们就是因为没设置,一不小心 5 天就把整个月的预算都烧光了……
优化提示词结构,尽量减少输出 Token 数量
你知道吗?OpenAI 平台上“输出 Token”的价格是“输入 Token”的 4 倍!
所以我们优化了模型的输出方式:不再让它输出完整的文本结果,而是改为只返回位置编号和类别,然后在代码中进行映射。这一个小改动,让我们的输出 Token 数量直接减少约 70%,调用延迟也大大降低!
使用 Batch API 处理非实时任务
如果你有不需要即时返回的任务,比如夜间批处理类操作,强烈推荐用 Batch API(一个专门设计来处理大量数据的批处理服务)!我们把一批夜间处理逻辑迁移到了 Batch API 上,直接省了一半的费用。虽然它有 24 小时的处理窗口,但对非实时业务完全没问题,强烈推荐。
写在最后:这些经验教训是我们在烧掉 94 亿个 Token 之后,边踩坑边总结出来的,希望能帮大家避雷。如果你也在做 AI API 集成,欢迎补充一些实用技巧!
“这值得烧掉 94 亿个 Token 吗?”
然而,对于上面的这些建议和总结,多数网友的第一反应都是:就这,值得烧掉 94 亿个 Token 吗?
也有部分网友提出疑问,为什么不试试其他更便宜的模型:
同时,个别开发者也指出,有些建议并不适用于所有情景:
CSDN创始人&董事长蒋涛「对谈」浙大求是特聘教授方兴东。作为中国互联网30年的见证者最新 Moonshot 接口,从鸿蒙操作系统的破晓之路,聊聊中国高科技的崛起之路。方兴东新书《鸿蒙开物》来了!直播间抽福袋价格最低 Mistral api key,领「限定签章版」。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...