

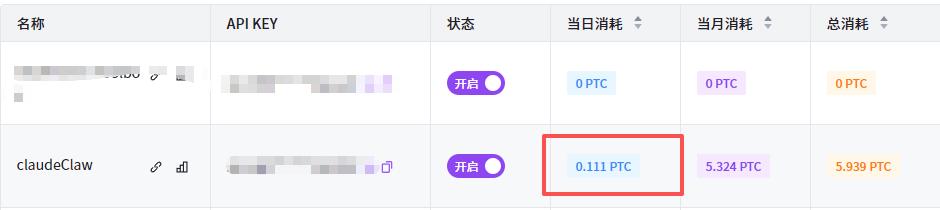
之前就听说openclaw用起来非常花钱,但也有省钱的办法。最近公司养了几只龙虾,也接上了性能最强的claude-sonnet-4.6、gpt5模型。我不敢让它执行复杂的任务,怕一不小心烧掉几百块。于是我在聊天框里打出了我认为最便宜的命令,“你好”。
查了一下账户消费记录,花费7毛钱(0.111美元)?!总共输入大约2万token。
怎么可能?我又在账户里调查了一番xAI api,原来我发出的“你好”,前面跟了上万字openclaw自带的系统提示词,而且几乎无法避免。连“你好”都这么贵api管理平台,真让它干活,钱包还受得了?正好我们至顶AI实验室手上有一些本地AI设备Ollama api key,比如英伟达GB10显卡系列的机器api项目,可以部署本地大模型。直接把openclaw接入的这些昂贵的云端付费模型换成免费的本地大模型。本地模型接入openclaw可能比较麻烦,不过别担心,下面我就教大家怎么操作。本地模型的部署方法有很多,我们这里主要讲常见的Ollama和vLLM接入方法。(注意:下载模型的时候Ollama api key,要选择可以调用工具的模型哦)Ollama
1.ollama下载模型
ollama pull gpt-oss:120b2..openclaw允许ollama
openclaw config set
models.providers.ollama.apiKey “ollama-local”3.修改配置文件
修改这个文件: ~/.openclaw/openclaw.json
{ agents: { defaults: { model: { primary: “ollama/gpt-oss:120b” }, }, },}给大家看看我修改完的示例,不一定跟我一样: “agents”: { “defaults”: { “model”: { “primary”: “ollama/gpt-oss:120b”, “fallbacks”:
“openai/gpt-5.1-codex”
}, “models”: { “ollama/gpt-oss:120b”: { “alias”: “GPT-OSS-120b” }4.检查是否成功openclaw models listollama模型,显示为default
openclaw能开启新对话则成功。
vLLM这里假设你已经部署好了vLLM,下载好了模型。1.启动vLLM模型
(以Qwen/Qwen3.5-35B-A3B 为例)
vllm serve Qwen/Qwen3.5-35B-A3B –enable-auto-tool-choice –tool-call-parser qwen3_coder–enable-auto-tool-choice
–tool-call-parser
这两个参数代表vllm允许自动调用工具
qwen3_coder
这个参数代表–tool-call-parser调用qwen3_coder。!不同模型对应的不一样,qwen3.5对应qwen3_coder。需要在你用的模型的huggingface上的Modelcard等地方查。!
2.在openclaw添加vLLM运行的模型
openclaw configure(1)选择 Local->Model->vLLM
(2)填入vLLM API key:
vllm-local(3)模型填入
Qwen/Qwen3.5-35B-A3B(4)检查是否成功openclaw models listvllm模型,显示为default
openclaw能开启新对话则成功。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...