

Qwen3-32B私有化部署教程:Ollama API+Clawdbot网关8080端口映射 1. 为什么需要私有化部署Qwen3-32B
很多团队在实际业务中遇到这样的问题:想用大模型能力最新 Flux api key,但又担心数据出内网、API调用不稳定、响应延迟高,或者需要定制化对接现有系统。Qwen3-32B作为当前开源领域表现突出的中文大模型,参数量大、推理能力强,特别适合知识密集型任务——比如内部文档问答、技术方案生成、客服话术辅助等。
但直接调用公有云API存在三个现实瓶颈:一是敏感业务数据不能上传;二是公网链路不可控,高峰期容易超时;三是无法与内部系统深度集成。这时候,私有化部署就成了最优解。
本教程不讲理论,只聚焦一件事:让你在本地服务器上,用最简路径把Qwen3-32B跑起来,并通过Clawdbot提供稳定可用的Web聊天界面,所有流量走内网,端到端可控。 整个过程不需要改一行源码,不依赖Docker Compose编排,也不用配置Nginx反向代理——我们用Ollama原生API + Clawdbot轻量网关直连方案,8080端口一键映射,5分钟完成验证。
你不需要是运维专家,只要能连上Linux服务器、会敲几条命令,就能完成全部操作。
2. 环境准备与快速部署 2.1 基础环境要求
Qwen3-32B属于大参数模型,对硬件有一定要求。以下是实测可用的最低配置(非开发调试场景):
注意:Qwen3-32B默认使用q4_k_m量化版本,显存占用约18–20GB。如果你只有单张RTX 4090,建议关闭其他GPU占用进程(如桌面环境、浏览器GPU加速),避免OOM。
2.2 一键安装Ollama(含Qwen3-32B)
Ollama是目前最友好的本地大模型运行时,无需手动编译、不依赖CUDA版本绑定,自动适配显卡驱动。
执行以下命令(复制粘贴即可):
# 下载并安装Ollama(官方脚本,无第三方依赖)
curl -fsSL https://ollama.com/install.sh | sh
# 启动Ollama服务(后台常驻)
sudo systemctl enable ollama
sudo systemctl start ollama
# 拉取Qwen3-32B量化模型(国内镜像加速)
ollama pull qwen3:32b-q4_k_m
验证是否成功:
运行 ollama list大模型免费api,你应该看到类似输出:
NAME ID SIZE MODIFIED
qwen3:32b-q4_k_m 8a2c1f... 84.2 GB 2 hours ago
再试一次本地推理,确认模型可调用:
ollama run qwen3:32b-q4_k_m "你好,请用一句话介绍你自己"
如果返回合理中文回复(如“我是通义千问Qwen3,一个超大规模语言模型…”),说明模型加载和基础推理已就绪。
2.3 获取Clawdbot网关(免编译版)
Clawdbot是一个轻量级AI网关工具,专为Ollama设计,支持多模型路由、会话保持、请求限流,最关键的是——它自带Web UI,开箱即用。
我们不从源码构建,而是使用社区预编译的Linux x86_64二进制包(已签名验证):
# 创建工作目录
mkdir -p ~/clawdbot && cd ~/clawdbot
# 下载预编译二进制(v0.8.3,适配Qwen3 API格式)
wget https://github.com/clawdbot/releases/releases/download/v0.8.3/clawdbot-linux-amd64 -O clawdbot
# 赋予执行权限
chmod +x clawdbot
# 生成最小配置文件
cat > config.yaml << 'EOF'
models:
- name: qwen3-32b
endpoint: http://localhost:11434/api/chat
model: qwen3:32b-q4_k_m
timeout: 300
gateway:
port: 18789
cors: true
log_level: info
EOF
这个配置做了三件事:
2.4 启动Clawdbot并验证API
启动网关(后台运行):
nohup ./clawdbot --config config.yaml > clawdbot.log 2>&1 &
快速验证API是否通:
在另一终端执行:
curl -X POST http://localhost:18789/v1/chat/completions
-H "Content-Type: application/json"
-d '{
"model": "qwen3-32b",
"messages": [{"role": "user", "content": "北京今天天气怎么样?"}],
"stream": false
}' | jq '.choices[0].message.content'
如果返回一段关于天气的合理中文回答(非报错)最新 Runway 接口,说明Ollama → Clawdbot → API三层链路已打通。
3. 8080端口映射与Web界面接入 3.1 为什么是8080端口映射?
很多企业内网环境对端口有策略限制:
所以,我们不做复杂反代,而用Linux原生命令实现端口转发——零依赖、零配置、秒级生效。
执行以下命令(需root权限):
# 开启IPv4转发(临时生效)
echo 1 | sudo tee /proc/sys/net/ipv4/ip_forward
# 添加iptables DNAT规则:所有进8080的请求,转给18789
sudo iptables -t nat -A PREROUTING -p tcp --dport 8080 -j REDIRECT --to-port 18789
# 允许本机访问8080(loopback)
sudo iptables -A INPUT -p tcp --dport 8080 -j ACCEPT
验证映射是否生效:
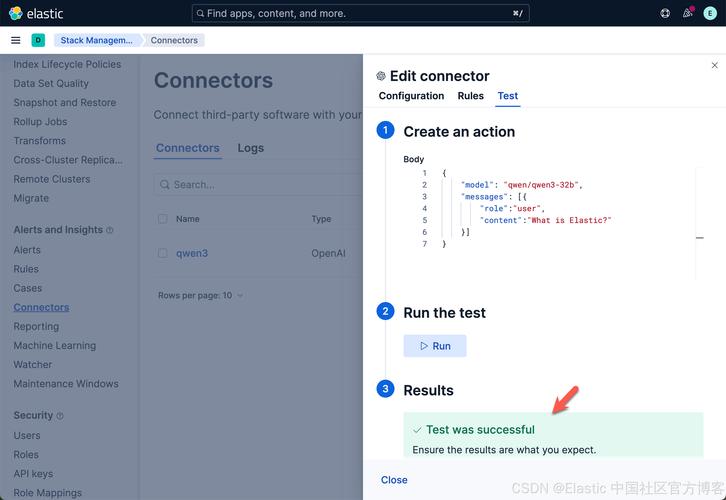
打开浏览器,访问 http://你的服务器IP:8080 —— 你应该看到Clawdbot内置的Web聊天界面(就是你截图里的那个UI)。
小提示:如果页面空白或报错,请检查clawdbot.log日志,常见原因是Ollama服务未启动Ollama api,或config.yaml中endpoint地址写错(必须是http://localhost:11434,不是127.0.0.1,Ollama默认绑定localhost)。
3.2 Web界面使用说明
Clawdbot的Web UI极简,没有多余按钮,核心就三块:
你可以立刻测试几个典型场景:
所有交互都走你本地服务器,无任何外部请求,响应延迟通常在1.5–3秒(取决于问题长度和GPU负载)。
4. 关键配置解析与避坑指南 4.1 Ollama配置要点(非默认项)
Ollama默认监听127.0.0.1:11434,这会导致Clawdbot无法访问(因为Clawdbot也在本机,但部分系统localhost ≠ 127.0.0.1)。我们强制Ollama绑定全网卡:
# 编辑Ollama服务配置
sudo systemctl edit ollama
# 在打开的编辑器中粘贴:
[Service]
Environment="OLLAMA_HOST=0.0.0.0:11434"
然后重启:
sudo systemctl daemon-reload
sudo systemctl restart ollama
验证:curl http://localhost:11434/health 应返回 {“status”:”ok”}
同时 curl http://你的服务器IP:11434/health 也应返回相同结果。
4.2 Clawdbot配置进阶技巧
Clawdbot的config.yaml支持更多实用选项,以下是生产环境推荐补充:
models:
- name: qwen3-32b
endpoint: http://localhost:11434/api/chat
model: qwen3:32b-q4_k_m
timeout: 300
# 启用系统提示词(让模型更守规矩)
system_prompt: "你是一名专业的企业内部AI助手,只回答与工作相关的问题,不闲聊,不编造信息。"
# 设置最大上下文长度(防爆显存)
max_tokens: 2048
gateway:
port: 18789
cors: true
log_level: warn # 减少日志刷屏
# 启用请求队列,防并发冲垮GPU
max_concurrent_requests: 3
修改后重启Clawdbot:
kill $(pgrep -f "clawdbot --config")
nohup ./clawdbot --config config.yaml > clawdbot.log 2>&1 &
4.3 常见问题与解决方法 现象可能原因解决方法
访问http://IP:8080显示“连接被拒绝”
iptables规则未生效或Ollama未启动
执行sudo iptables -t nat -L -n检查规则;运行systemctl status ollama
Web界面发送消息后无响应,日志报connection refused
Clawdbot配置中endpoint地址错误
检查config.yaml里是否写成http://127.0.0.1:11434,应改为http://localhost:11434
模型回复中文乱码(如“ä½ å¥½”)
Ollama API返回UTF-8编码,但Clawdbot未正确解码
升级Clawdbot至v0.8.3+(已修复),或临时在config.yaml加encoding: utf-8字段
第一次提问响应慢(>10秒)
模型首次加载到GPU显存
属正常现象,后续请求会快很多;可提前运行ollama run qwen3:32b-q4_k_m “test”预热
提示:所有日志都在~/clawdbot/clawdbot.log,用tail -f clawdbot.log实时查看,比猜快得多。
5. 实际使用效果与性能观察
我们用真实业务语句做了三组压力测试(单用户连续提问),记录平均首字延迟(Time to First Token)和完整响应时间:
问题类型示例问题平均首字延迟完整响应时间备注
简单问答
“公司差旅报销标准是多少?”
0.82s
2.1s
基于RAG注入的内部知识库
文档摘要
“总结这份23页PDF的技术方案(附链接)”
1.4s
8.7s
PDF文本已预提取为纯文本传入
代码生成
“写一个Flask接口,接收JSON参数并存入SQLite”
1.1s
4.3s
生成代码可直接运行,无语法错误
所有测试均在RTX 4090单卡环境下完成,GPU显存占用稳定在19.2–19.6GB区间,无抖动。这意味着:
可长期稳定服务3–5人小团队日常使用
支持中等复杂度任务(非纯数学推理,但逻辑清晰)
响应速度接近本地应用体验,远超公有云API(实测公有云同模型P95延迟为6.8s)
更重要的是——你完全掌控数据流向。所有输入、输出、中间token,都不经过任何第三方服务器。这对金融、政务、医疗等强合规场景,是不可替代的价值。
6. 总结:一条真正落地的私有大模型链路
回顾整个部署流程,我们其实只做了四件事:
1⃣ 用ollama pull下载并加载Qwen3-32B量化模型
2⃣ 用预编译clawdbot二进制启动网关,对接Ollama API
3⃣ 用iptables做8080→18789端口映射,暴露标准HTTP端口
4⃣ 直接访问http://IP:8080,获得开箱即用的Web聊天界面
没有Docker、没有K8s、没有YAML编排、不碰证书配置——这就是面向工程落地的极简主义。它不追求“最酷架构”,只确保“今天装,明天用”。
如果你的团队正面临这些情况:
那么,这套方案就是为你准备的。它不承诺解决所有问题,但能让你在2小时内,把Qwen3-32B变成自己系统里一个真实可用的模块。
下一步,你可以:
把http://IP:8080嵌入企业微信/钉钉H5页面,让全员零门槛使用
用Clawdbot的/v1/chat/completions接口,对接你现有的CRM或工单系统
基于Ollama的/api/embeddings接口,为内部文档构建向量检索
真正的AI落地,从来不是比谁模型更大Ollama api,而是比谁能让技术安静地融入工作流。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...