

Chandra入门指南:理解Ollama API接口、Chandra前端通信与本地推理流程 1. 引言:为什么选择本地AI聊天助手?
想象一下,你有一个随时待命的智能助手,它能和你聊天、帮你写东西、回答你的问题,而且最棒的是——它完全在你的电脑或服务器上运行。你不用担心聊天内容被上传到云端,也不用忍受网络延迟带来的卡顿。这就是Chandra带来的体验。
Chandra是一个基于Ollama框架的本地AI聊天应用。它把整个智能对话系统“装进”了一个容器里,从模型推理到前端界面,全部在本地完成。这意味着:
本文将带你深入理解Chandra的工作原理,从Ollama的API接口,到前端如何与后端通信Ollama api,再到模型如何在本地完成推理。读完这篇文章,你不仅能熟练使用Chandra,还能理解背后的技术逻辑。
2. 核心组件解析:Ollama与Chandra如何协同工作 2.1 Ollama:本地大模型的“发动机”
Ollama是一个专门为在个人电脑或服务器上运行大型语言模型而设计的框架。你可以把它想象成一个“模型容器管理器”,它做了三件关键的事情:
模型管理:帮你下载、更新、删除各种AI模型推理服务:提供标准的API接口,让其他应用可以调用模型能力资源优化:自动调整模型运行时的内存和计算资源使用
在Chandra镜像中价格最低 chatgpt 接口,Ollama已经预先安装并配置好了。它默认搭载了Google的gemma:2b模型——这是一个只有20亿参数的轻量级模型,虽然参数少,但在日常对话、写作辅助等任务上表现相当不错,而且对硬件要求很低。
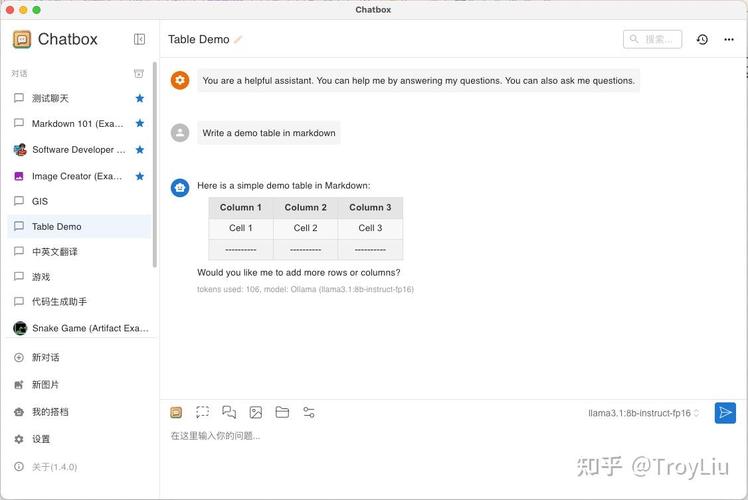
2.2 Chandra前端:简洁优雅的聊天界面
Chandra这个名字来自梵语,意为“月神”,象征着智慧。作为前端应用,Chandra提供了一个干净、直观的聊天界面。它的设计哲学是“少即是多”——没有复杂的设置选项,没有令人眼花缭乱的功能按钮,只有一个清晰的对话区域和一个输入框。
但简洁不代表简单。Chandra前端实际上做了很多智能的工作:
2.3 它们如何配合?
整个系统的工作流程可以概括为:
用户输入 → Chandra前端 → Ollama API → Gemma模型推理 → Ollama API → Chandra前端 → 用户看到回复
这个过程完全在容器内部完成,形成了一个封闭的、自给自足的AI对话系统。
3. 快速上手:10分钟开始你的第一次本地AI对话 3.1 启动与等待
当你启动Chandra镜像后Ollama api,系统会自动执行一系列初始化操作。这个过程通常需要1-2分钟,具体时间取决于你的服务器性能。系统在后台做了这些事情:
检查并确保Ollama服务正常运行如果还没有gemma:2b模型,会自动从镜像源下载加载模型到内存中,准备接收请求启动Chandra的Web界面服务
你可能会在日志中看到类似这样的信息:
正在拉取 gemma:2b 模型...
模型下载完成,正在加载...
Ollama服务已启动,监听端口11434
Chandra Web界面已启动,访问地址:http://localhost:8080
重要提示:请耐心等待这些过程完成。如果过早尝试访问,可能会遇到连接错误。
3.2 访问聊天界面
等待初始化完成后,你可以通过平台提供的访问地址进入Chandra。通常你会看到一个标有“HTTP”或“访问地址”的按钮,点击它就能在浏览器中打开聊天界面。
界面非常简洁:
3.3 开始第一次对话
试着输入一些简单的内容来测试系统是否正常工作:
你好,请介绍一下你自己。
按下回车键后,你应该会看到回复以流式的方式逐渐显示出来。如果一切正常,Chandra会告诉你它是一个由Ollama驱动的本地AI助手,并简单说明自己的能力。
再试试一些更有趣的:
给我写一个关于程序员和咖啡的简短笑话。
或者用英文测试:
Explain quantum computing in simple terms.
3.4 基础使用技巧
为了让对话更顺畅,这里有几个小建议:
4. 技术深潜:理解API通信与推理流程 4.1 Ollama API接口详解
Ollama提供了一套RESTful API价格最低 克罗德 接口,这是Chandra前端与模型后端通信的桥梁。最重要的两个端点是:
生成对话接口:
POST http://localhost:11434/api/generate
这个接口接收JSON格式的请求,最基本的格式是:
{
"model": "gemma:2b",
"prompt": "你好,今天天气怎么样?",
"stream": true
}
对话接口(支持多轮对话):
POST http://localhost:11434/api/chat
这个接口支持更复杂的对话场景,可以携带完整的对话历史:
{
"model": "gemma:2b",
"messages": [
{"role": "user", "content": "什么是人工智能?"},
{"role": "assistant", "content": "人工智能是...(之前的回答)"},
{"role": "user", "content": "那机器学习和人工智能有什么区别?"}
],
"stream": true
}
4.2 Chandra前端如何调用API
Chandra前端使用JavaScript的Fetch API或类似技术来与Ollama后端通信。下面是一个简化的代码示例,展示了前端是如何工作的:
// 发送消息到Ollama并获取流式响应
async function sendMessageToOllama(userInput) {
const response = await fetch('http://localhost:11434/api/generate', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
},
body: JSON.stringify({
model: 'gemma:2b',
prompt: userInput,
stream: true
})
});
// 处理流式响应
const reader = response.body.getReader();
const decoder = new TextDecoder();
let fullResponse = '';
while (true) {
const { done, value } = await reader.read();
if (done) break;
// 解码并处理每一块数据
const chunk = decoder.decode(value);
const lines = chunk.split('n').filter(line => line.trim());
for (const line of lines) {
try {
const data = JSON.parse(line);
if (data.response) {
fullResponse += data.response;
// 实时更新界面显示
updateChatDisplay(fullResponse);
}
} catch (e) {
console.error('解析响应出错:', e);
}
}
}
return fullResponse;
}
这段代码的关键点:
使用fetch向Ollama的API发送POST请求设置stream: true来获取流式响应通过ReadableStream逐块读取响应数据每收到一块数据就立即更新界面,实现打字机效果 4.3 本地推理流程解析
当你的问题从前端发送到Ollama后,在后台发生了什么呢?
步骤1:请求接收与解析 Ollama服务接收到HTTP请求,解析JSON数据,提取出模型名称和提示词。
步骤2:模型加载与准备 如果gemma:2b模型还没有加载到内存中,Ollama会从磁盘加载它。由于gemma:2b是轻量级模型,这个过程通常很快。
步骤3:文本编码 模型不能直接理解文字,所以需要将你的问题转换成数字表示(称为tokenization)。例如,“你好”可能会被转换成
1234, 5678
这样的数字序列。
步骤4:推理计算 这是最核心的一步。模型基于它的“知识”(来自训练数据)和你的问题,逐个token地生成回答。对于gemma:2b这样的模型,这个计算完全在CPU或GPU上进行,不依赖任何外部服务。
步骤5:文本解码与流式返回 模型生成的数字序列被转换回文字。由于设置了流式响应,Ollama不会等全部文字生成完再返回,而是每生成一小段就立即发送给前端。
步骤6:资源管理 对话完成后最新 Ideogram 接口,Ollama会管理模型占用的内存。如果有多个请求,它会高效地处理并发。
4.4 性能与资源考虑
gemma:2b模型之所以被选为默认模型,是因为它在性能和效果之间取得了很好的平衡:
特性gemma:2b 模型说明
参数规模
20亿
相比动辄千亿的大模型,非常轻量
内存占用
约4GB RAM
大多数现代电脑和服务器都能轻松运行
响应速度
极快
简单的问答通常在1-3秒内完成
对话质量
日常使用足够
能处理大多数聊天、写作、问答任务
支持语言
多语言,中文良好
对中文有不错的支持能力
如果你有更强的硬件,也可以通过Ollama轻松切换其他模型,比如更大的gemma:7b或专门优化中文的qwen系列模型。
5. 实际应用场景与技巧 5.1 适合的使用场景
Chandra虽然简洁,但能在很多实际场景中发挥作用:
个人学习与思考
工作辅助
开发与测试
5.2 提升对话效果的技巧
明确你的需求 与其问“帮我写点东西”,不如具体说明:
请帮我写一封给客户的邮件,内容是通知产品更新,语气要专业但友好。
提供上下文 如果问题涉及之前的对话,可以简要提及:
刚才我们讨论了神经网络,那么卷积神经网络和循环神经网络主要区别是什么?
控制回答长度 如果你需要简短或详细的回答,可以明确指定:
用一句话解释区块链技术。
或者:
详细说明机器学习从数据准备到模型部署的完整流程,分步骤解释。
迭代优化 如果第一次回答不理想,不要放弃。尝试:
5.3 技术集成示例
如果你是一名开发者,可能会想在自己的应用中集成类似的能力。以下是一个简单的Python示例,展示如何直接调用Ollama API:
import requests
import json
def ask_ollama(question, model="gemma:2b"):
"""向本地Ollama服务提问"""
url = "http://localhost:11434/api/generate"
payload = {
"model": model,
"prompt": question,
"stream": False # 设为False获取完整响应
}
try:
response = requests.post(url, json=payload, timeout=30)
response.raise_for_status()
result = response.json()
return result.get("response", "未获取到回答")
except requests.exceptions.RequestException as e:
return f"请求出错: {str(e)}"
# 使用示例
if __name__ == "__main__":
answer = ask_ollama("Python中的列表和元组有什么区别?")
print("AI回答:", answer)
# 流式响应版本
def ask_ollama_stream(question, model="gemma:2b"):
url = "http://localhost:11434/api/generate"
payload = {
"model": model,
"prompt": question,
"stream": True
}
response = requests.post(url, json=payload, stream=True, timeout=30)
print("开始流式响应:")
for line in response.iter_lines():
if line:
try:
data = json.loads(line.decode('utf-8'))
if "response" in data:
print(data["response"], end="", flush=True)
except json.JSONDecodeError:
continue
print() # 换行
# 测试流式响应
ask_ollama_stream("讲一个简短的寓言故事")
6. 常见问题与故障排除 6.1 启动与连接问题
问题:访问界面时显示连接错误
可能原因2:端口被占用或配置错误
问题:模型加载失败
6.2 对话相关问题
问题:回答速度很慢
可能原因2:问题过于复杂
问题:回答质量不理想
6.3 高级配置与优化
如何更换其他模型? 虽然Chandra默认使用gemma:2b,但你可以通过进入容器终端来管理模型:
# 进入容器(具体命令取决于你的部署平台)
docker exec -it chandra_container /bin/bash
# 在容器内使用Ollama命令
ollama pull llama2:7b # 下载其他模型
ollama list # 查看已安装的模型
如何调整服务配置? Ollama的配置文件通常位于/etc/ollama/或用户目录下的.ollama/中。你可以调整:
7. 总结
通过本文的讲解,你应该对Chandra有了全面的理解——从它是一个什么样的应用,到它背后的技术原理,再到如何有效使用它。
Chandra的核心价值在于它提供了一个完全本地化、隐私安全、开箱即用的AI对话解决方案。它把复杂的模型部署和API对接封装成了简单的Web界面,让任何人都能轻松体验本地AI的能力。
关键要点回顾:
隐私与速度优势:所有数据处理都在本地完成,既保护隐私又提升响应速度技术栈清晰:Ollama负责模型推理,Chandra提供友好界面,两者通过标准API通信使用简单直接:无需复杂配置,启动后即可开始对话资源要求友好:默认的gemma:2b模型对硬件要求很低扩展性强:理解原理后,你可以定制前端或集成到自己的应用中
无论你是想体验本地AI对话,还是学习AI应用集成,或是需要一个隐私安全的写作助手,Chandra都是一个很好的起点。它的设计哲学——简洁、实用、隐私优先——代表了AI工具发展的一个重要方向。
现在,你已经掌握了Chandra的完整知识。接下来就是动手实践的时候了。启动你的Chandra实例,开始一段完全属于你自己的、私密的AI对话之旅吧。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...